NoSQL e Teorema CAP: perchè la partition tolerance risulta oggi essere il miglior compromesso
L’universo delle tecnologie digitali è al giorno d’oggi in continua evoluzione. In particolare, la quantità di dati da elaborare sembra crescere a dismisura. Sempre più di frequente le applicazioni richieste sul mercato necessitano di accedere a informazioni molto diverse tra loro e, soprattutto, dislocate in archivi differenti (database, file, server o repository di altra natura). La spinta continua a garantire prestazioni sufficienti a elaborare questo enorme flusso di dati richiede di poter disporre di sistemi facilmente scalabili in base alle esigenze; uno dei requisiti forti è inoltre la possibilità di aumentare il numero dei nodi a disposizione a caldo, senza cioè che il sistema debba essere arrestato e riavviato successivamente. All’interno di questo articolo, vedremo il Teorema CAP e la sua applicazione al mondo NoSQL, e le motivazioni per le quali dar priorità alla partition tolerance (come accaduto nel caso del DB Cassandra) è oggi la scelta migliore.
CONSISTENCY, AVAILABILITY E PARTITION TOLERANCE: TEOREMA CAP E RELATIVE IMPLICAZIONI
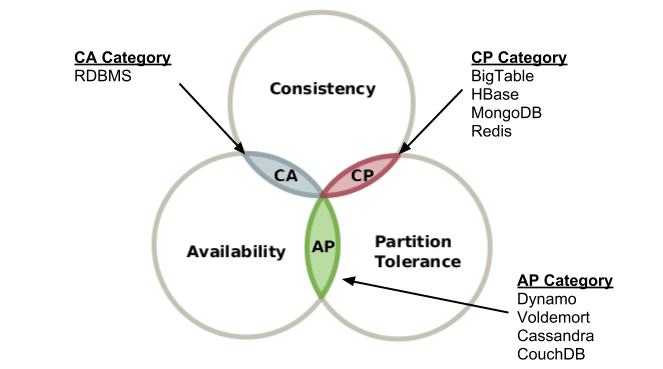
Alcune delle caratteristiche accennate in apertura rientrano tra i punti di forza che gli utenti cercano in un sistema distribuito: consistency, availability, partition tolerance. Le tre iniziali in fila, CAP, formano un acronimo ricorrente nell’ambito informatico che dà a sua volta il nome a un importante teorema, noto appunto come Teorema CAP (o Teorema di Brewer). L’enunciato prende forma come congettura nel 2000 presso l’università di Berkeley, in California; ci pensano successivamente Seth Gilbert e Nancy Lynch del MIT, nel 2002, a fornire una dimostrazione formale della congettura trasformandola in un teorema a tutti gli effetti. Le conclusioni teoriche di Brewer, Gilbert e Lynch ci mettono in guardia rispetto all’impossibilità di fornire simultaneamente per un sistema distribuito tutte e tre le seguenti garanzie racchiuse nell’acronimo.
Fonte: http://eincs.com/2013/07/misleading-and-truth-of-cap-theorem/
Vale comunque la pena di esplorare più a fondo il significato delle singole proprietà associate a ciascuna lettera. La Consistenza (C) è legata alla necessità che tutti i nodi connessi al sistema vedano gli stessi dati in uno stesso momento: in altre parole deve essere possibile poter leggere uno stesso dato contemporaneamente da diversi nodi e ottenere lo stesso valore. La seconda iniziale, la A di Availability, è associata alla possibilità che a ogni richiesta segua sempre e comunque una risposta, positiva o negativa, riguardo l’esito dell’invocazione; in altre parole deve essere sempre possibile poter accedere al sistema anche al venir meno di uno dei nodi che lo compongono. L’ultima lettera, la P, indica la partition tolerance, ovvero la capacità del sistema di continuare a funzionare correttamente anche se e quando venga meno la connessione tra i nodi.
Secondo il teorema di Brewer, un sistema distribuito è in grado di soddisfare al massimo due di queste proprietà allo stesso tempo, ma non tutte e tre. Alla luce di questo limite, per niente banale, l’utente è chiamato a fare una scelta relativa alla proprietà a cui è disposto a rinunciare. Una delle linee adottate sempre più di frequente consiste nel sacrificare la consistenza (C) in cambio di una maggiore robustezza rispetto al fallimento di uno o più nodi o a eventuali problemi di comunicazione (A e P). Un interessante articolo (https://docs.microsoft.com/en-us/azure/architecture/patterns/compensating-transaction) pubblicato sul sito di Microsoft sembra andare in questa direzione, offrendo tra l’altro ulteriori spunti circa la possibilità di rinunciare a un modello strong transactional consistency in favore di una più adatta e funzionale eventual consistency.
Tentando di sintetizzare il contenuto dell’articolo, la sfida più impegnativa, nell’applicare un modello di eventual consistency, consiste nel gestire il fallimento di uno o più step all’interno di un workflow. Non è detto che il rollback sia semplice o sempre possibile, dal momento che altre applicazioni concorrenti potrebbero avere letto, usato e modificato a loro volta gli stessi dati. Vincoli specifici legati all’applicazione potrebbero inoltre impattare sulla possibilità di riportare i dati al valore iniziale.
Più in generale, non è detto che tornare indietro equivalga a riportare i dati a uno stato originario. Si prenda ad esempio un sistema di prenotazioni legato a un’agenzia viaggi: acquistare un intero viaggio potrebbe richiedere la prenotazione di diversi voli e alberghi dislocati nelle varie città (un volo dalla città A alla città B, un albergo nella città B e infine un volo successivo dalla città B alla città C). Implementare una transazione compensativa comporta affrontare svariate difficoltà, a partire dal fatto che i singoli passaggi legati alla procedura di rollback potrebbero non coincidere con l’esatto ordine inverso delle prenotazioni (la cancellazione del primo volo e della prenotazione dell’albergo potrebbero avvenire ad esempio in parallelo o nello stesso ordine in cui sono stati effettuati gli acquisti); riguardo invece ai vincoli specifici, potrebbe non essere possibile restituire al cliente l’intero ammontare di denaro che ha speso per prenotare uno dei biglietti aerei. Per questo e altri motivi, la logica associata alla transazione potrebbe essere legata in maniera specifica al contesto dell’applicazione.
LE SCELTE DI CASSANDRA ED ALTRI DB NoSQL IN AMBITO CAP: QUALE BINOMIO PREDILIGERE?
È interessante a questo punto prendere in considerazione dove e come si posizionano alcuni dei principali sistemi di gestione dati rispetto alla scelta di quante e quali garanzie offrire all’utente in uno scenario distribuito.
Sistemi di gestione dati relazionali, come ad esempio, MySQL o PostgreSQL puntano sul binomio CA (Consistency e Availability): i dati rimangono coerenti su tutti i nodi, almeno finché i nodi sono online e riescono a comunicare tra loro, e sarà possibile ottenere uno stesso valore interrogando il medesimo dato su nodi differenti. Sistemi come Hbase, MongoDB, Redis e Memcache nascono almeno in origine come soluzioni CP oriented (Consistency e Partition tolerance): i dati rimangono coerenti rispetto ai vari nodi e viene garantita una tolleranza rispetto a eventuali interruzioni della comunicazione tra i nodi stessi, ma i dati potrebbero diventare inaccessibili al venir meno di uno dei nodi. Infine sistemi come CouchDB, DynamoDB e non ultimo Cassandra puntano al binomio AP (Availability e Partition tolerance). Rinunciano cioè alla consistenza in cambio di prestazioni più solide rispetto alla variazione del numero dei nodi e a momentanei problemi di comunicazione tra i singoli nodi.
Fonte: https://mytechnetknowhows.wordpress.com/2016/05/31/cap-theorem-consistency-availability-and-partition-tolerance/
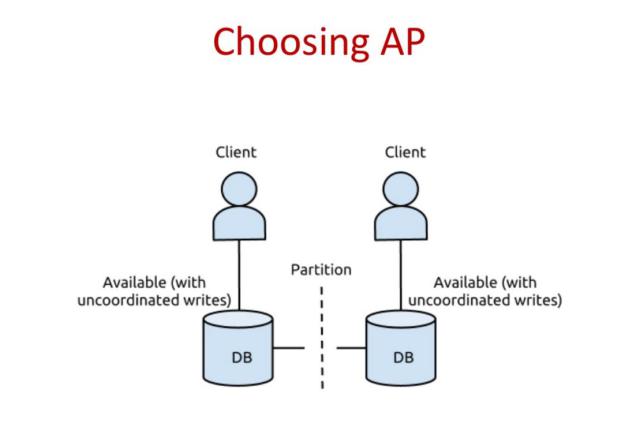
In un sistema distribuito capace di rispettare le proprietà AP non è garantito che interrogando nodi diversi riguardo uno stesso dato si ottenga lo stesso valore, ma la coerenza dei dati verrà comunque assicurata in un lasso di tempo ragionevole (da cui la definizione di sistemi eventually consistent).
Sistemi con queste caratteristiche riescono inoltre a rimanere in piedi anche in seguito alla caduta di uno o più nodi; inoltre i nodi rimangono online anche se per dei brevi periodi non riescono a comunicare tra loro. Rispetto alle alternative CA e CP, il binomio AP sembra essere quello che più va incontro alle caratteristiche richieste oggi dal mercato.
Ovvero, applicazioni capaci di leggere e processare in tempi brevi dati provenienti da sorgenti diverse dislocati in locazioni geografiche differenti.
Per questa ragione sistemi basati su Cassandra come Isaac, che sin dalla nascita rispettano questo binomio, sembrano essere i più adatti ad affrontare e sostenere le sfide del futuro.
