NoSQL and CAP Theorem: why partition tolerance is now the best compromise
The universe of digital technologies is constantly evolving . The amount of data to be processed seems to be growing dramatically. Always more applications on the market need access to very different information and, above all, located in different archives (databases, files, servers or repositories of other nature). The push to provide sufficient performance standards to process this huge stream of data requires you to have systems that are easily scalable; one of the strong requirements is also the possibility of increasing the number of available nodes, i.e. without the system having to be shut down and restarted later. Within this article, we will see the CAP Theorem and its application to the NoSQL world, and the reasons why prioritizing partition tolerance (as happened in the case of the DB Cassandra) is today the best choice.
CONSISTENCY, AVAILABILITY AND PARTITION TOLERANCE: CAP THEOREM AND ITS IMPLICATIONS
Some of the features mentioned in the opening are among the strengths that users are looking for in a distributed system: consistency, availability, partition tolerance. The three initials in a row, CAP, form a recurring acronym in the computer field that gives its name to an important theorem, known precisely as the CAP Theorem (or Brewer’s Theorem). The statement takes shape as a conjecture in 2000 at the University of Berkeley, California; Seth Gilbert and Nancy Lynch of MIT, in 2002, put it a formal demonstration of conjecture and turned it into a full-fledged theorem. The theoretical conclusions of Brewer, Gilbert and Lynch warn us of the impossibility of simultaneously providing all three of the following guarantees enclosed in the acronym for a distributed system.
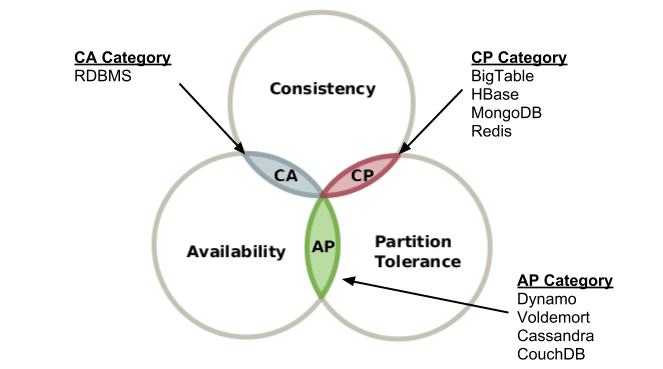
Image source: http://eincs.com/2013/07/misleading-and-truth-of-cap-theorem/
However, it is worth exploring more deeply the meaning of the individual properties associated with each letter. Consistency (C) is linked to the need for all nodes connected to the system to see the same data at the same time: in other words, it must be possible to read the same data at the same time from different nodes and get the same value. The second initial, the A of Availability, is associated with the possibility that each request will always follow a positive or negative response about the outcome of the invocation; in other words, it must always be possible to access the system even when one of its nodes fails. The last letter, the P, indicates partition tolerance, which is the ability of the system to continue to function properly even if and when the connection between the nodes fails.
According to Brewer’s theorem, a distributed system is able to satisfy at most two of these properties at the same time, but not all three. In light of this limit, not at all trivial, the user is called to make a choice related to the property to which he is willing to give up. One of the lines adopted more and more frequently is to sacrifice consistency (C) in exchange for greater robustness than the failure of one or more nodes or any communication problems (A and P). An interesting article (https://docs.microsoft.com/en-us/azure/architecture/patterns/compensating-transaction) published on Microsoft’s website seems to be going in this direction, offering, among other things, further insights into the possibility of giving up a strong transactional consistency model in favor of a more suitable and functional eventual consistency.
Attempting to summarize the content of the article, the most challenging challenge, in applying an eventual consistency model, is to manage the failure of one or more steps within a workflow. It is not said that rollback is simple or always possible, since other competing applications may have read, used, and modified the same data. Application-specific constraints could also impact the ability to return data to its initial value.
More generally, it is not said that going back is equivalent to returning the data to its original state. Take, for example, a booking system linked to a travel agency: buying an entire trip may require booking several flights and hotels located in various cities (a flight from city A to city B, a hotel in city B, and finally a subsequent flight from city B to city C). Implementing a compensatory transaction faces a number of challenges, starting with the fact that the individual steps related to the rollback procedure may not coincide with the exact reverse order of bookings (the cancellation of the first flight and hotel booking could be in parallel or in the same order in which the purchases were made); with regard to the specific constraints, it may not be possible to return to the customer the full amount of money he spent on booking one of the airline tickets. For this and other reasons, the logic associated with the transaction may be specifically tied to the application context.
CASSANDRA AND OTHER NoSQL DB IN CAP FIELD: WHICH BINOMIAL TO PREFER?
It’s interesting at this point to consider where and how some of the major data management systems are positioned in relation to choosing how many and what guarantees to offer the user in a distributed scenario.
Relational data management systems, such as MySQL or PostgreSQL, rely on the CA (Consistency and Availability) pairing: data remains consistent on all nodes, at least as long as the nodes are online and can communicate with each other, and you can get the same value by querying the same data on different nodes. Systems such as Hbase, MongoDB, Redis, and Memcache are originally created as CP oriented (Consistency and Partition tolerance) solutions: data remains consistent with the various nodes and tolerance is guaranteed with respect to any disruption of communication between the nodes, but the data may become inaccessible when one of the nodes fails. Finally, systems such as CouchDB, DynamoDB and not least Cassandra point to the AP (Availability and Partition tolerance) combination. That is, they give up consistency in exchange for more robust performance than the change in the number of nodes and momentary communication problems between the individual nodes.
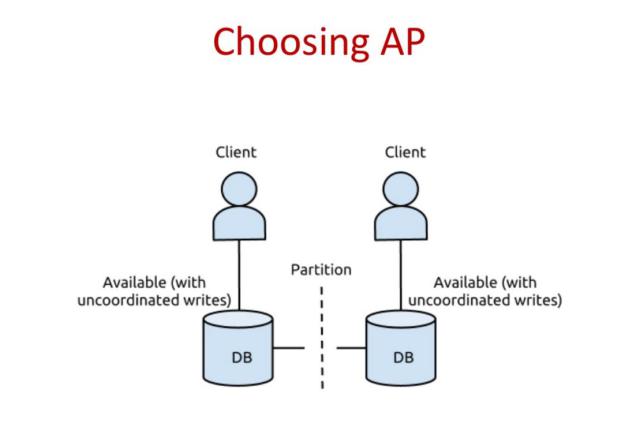
Image source: https://mytechnetknowhows.wordpress.com/2016/05/31/cap-theorem-consistency-availability-and-partition-tolerance/
In a distributed system that respects AP properties, it is not guaranteed that querying different nodes for the same data will get the same value, but the consistency of data will still be ensured in a reasonable amount of time (hence the definition of eventually consistent systems).
Systems with these characteristics also manage to stay upright even after the fall of one or more nodes; In addition, the nodes remain online even if they cannot communicate with each other for short periods. Compared to the CA and CP alternatives, the AP pairing seems to be the one that most meets the characteristics required today by the market.
That is, applications that can quickly read and process data from different sources located in different geographical locations.
For this reason, Cassandra-based systems such as Isaac, which from birth respect this combination, seem to be the most suitable to face and support the challenges of the future.
